You may have suffered ‘death by join’ and not even know it!
Most of us have done this, maybe even twice. You get into an organization, meet with your stakeholders, gather requirements, pick a risk management framework, and start to look for which platform you are going to use to manage your risk programs. You spend hours configuring, or worse, paying for custom coding to necessary requirements. All looks good to go and you start to use the platform. You begin launching assessments to the first line of defense and feed copious amounts of risk telemetry from your various platforms. You build complex cross-references that start to outline what the risk universe actually looks like. Then the record sets begin to grow, starting slow but growing exponentially, from 100’s of sets to 10’s of thousands or more.
Then it happens! The screen refreshes start to slow down, followed by the inevitable: an audit, a Board Report Out, or worse, a major incident and you have to start to leverage all of your efforts. You go to the reporting engine and start to build out your reports, many of which might require reporting on those cross-references (degrees of separation) three or more levels deep. Holding your breath, you click the run button and the refresh button spins….and spins….and spins. If you’re lucky and the function does not time out, you might actually get a result. If you’re not, you get to start over.
Welcome to what we call in the database world ‘death by join.’
Most of the GRC platforms are still running on database architectures from the dawn of GRC when they first started addressing risk using something besides spreadsheets and SharePoint. What’s now clear is that Relational Database backends were simply not designed to address the complexities of risk management at scale.
What is Risk Management at scale?
Risk management is naturally hierarchical and structured in almost a chain-like manner. Each link of the chain is made up of various data points needed to perform effective risk management. The following are just a few examples of these chains, which are also interrelated in a complex mapping of cross-references and relationships.
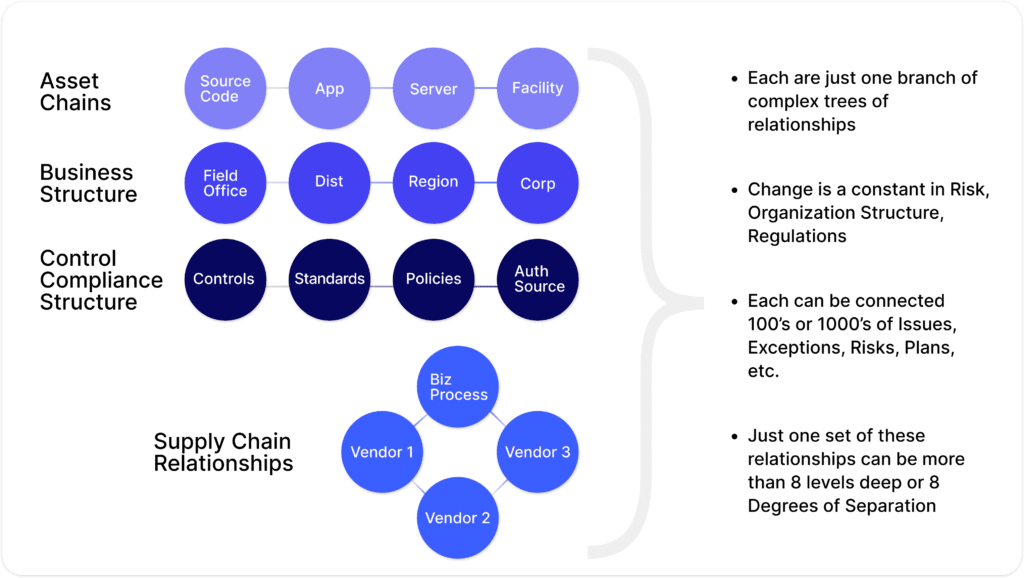
If we explore the depth of a variety of our organizational structures and how they tie into rolling up risks and other data points, the connections within the risk network become even more complex. Each level with its own policies, risks, issues, exceptions, continuity plans, third-party relationships, and so on. This complex intertwining of the circles (nodes) and their joining relationships (edges) is what is known as a ‘graph.’ This term tends to confuse many business users when they first hear it in this context. They typically think this refers to charts of data. However, innovators in the industry have known for years now that risk management is a highly networked problem, or more simply put, a graph problem.
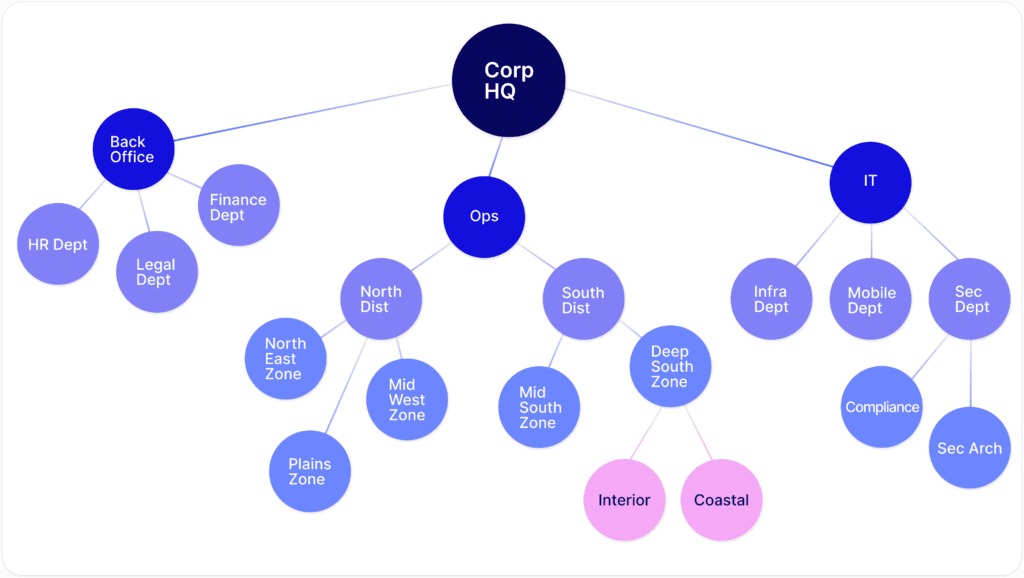
So…..what does it look like to manage risk at scale? To put it simply, risk management is addressing a graph built from connections of risks, organizations, 3rd parties, findings, policies, plans, etc.

The Dirty Secret of GRC Platforms…
Legacy GRC platforms layered these complex graphs on top of traditional relational databases, most of whose underlying structures haven’t been changed in decades. It is also much of the underlying reason why you hear these platforms get criticized for being “clunky,” “slow,” or “hard to use.” When you hear this, it means that under the covers it is likely, ‘death by join’ is happening. As with most things, there are short-term fixes: adding new indexes, tuning existing indexes, schema redesigns, etc. Even more shocking, some platforms in this position are moving the exact same platforms straight to the cloud. This places greater loads on a strained infrastructure, which comes with higher SaaS operating price tags as these systems come under extreme loads. Just throwing more processing power at a problem is not always the right answer and can be quite costly in the long run.
Graph Database architecture, on the other hand, was purpose-built to address these issues natively. This database style isn’t new, it’s actually decades old itself, with origins in the 1970s. Relational databases only took over mainly due to our need for transactional processing in finance and manufacturing. Graph databases lived on, relegated to addressing complex engineering problems like laminar flow analysis.
Then a funny thing happened in the 2000s: massive, complex networks began being built, for example, those behind Netflix and Facebook. Graph databases had a bit of a re-emergence, but many legacy GRC companies continued to ignore its application. Graph databases excel at dealing with these highly networked problems where relational database systems quickly fall over and fail. As an example, the following chart is taken from a NEO4J study. You’ll notice that at the fifth degree of separation (5th join), the SQL execution is already showing failure.
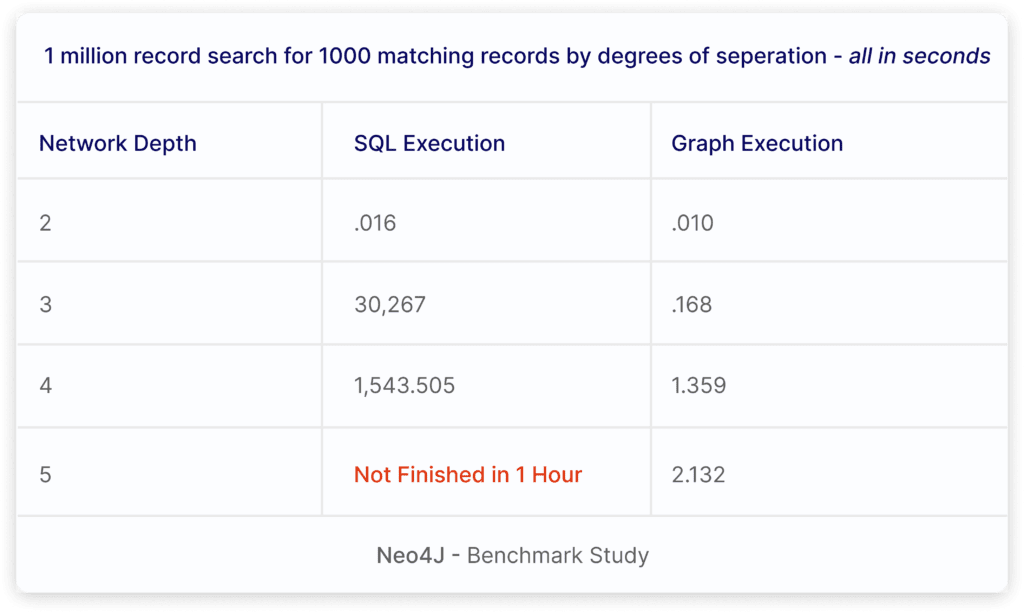
For example, have you ever tried to run a complex report in a GRC platform asking a complex network-based risk question like, “Based on a specific regulation section which organizational units still have open findings on specific controls that lack remediation plans or have granted exceptions?” This is an example of a five-degree-of-separation question (I’ve bolded the nodes in the question.)
In almost every case, this query in a relational database structure could take more than an hour to finish, that is if it ever finishes. Yet, you likely wouldn’t find out your report won’t run until the board asks this kind of question when your competitor gets a massive fine. “The board would like to know our organization’s risk posture in this risk scenario”. This is the dirty secret of most GRC platforms: you spend inordinate amounts of time getting the data in, but in many cases, you cannot get the data out in a timely manner…if at all!
Surviving Death!
I have long been a fan of graph database architecture, looking at its applications in combating other complex network problems such as fraud and logistics optimization. In the risk space, I’ve consistently pushed for companies to explore how it could be used to address the complex network issues in the GRC space. Unfortunately, there has been a pervasive “if people are still buying it, what is there to fix?” type of view. In most cases, I am not convinced that they actually understood the real problem or that GRC is a graph at its most basic level. Then, last year I was quite excited when I found that at its core LogicGate had deployed Neo4J, which is a graph database. Besides the great culture in the organization, this single fact led me to join the company. It’s clear that they have the architecture that is needed to deal with an ever-evolving set of waves of regulation, threats, and remediation. You can now scale your risk programs without the fear of the dreaded ‘death by join!’